# 记一次队列使用不当导致的OOM问题
背景:最近换了家做SAAS的公司,我负责了直播那块的业务。有一家KA客户周四晚上直播时,服务频繁重启,即使开了十几个节点都无法有效支撑一万同时在线人数的稳定的服务质量。记录一下OOM的排查过程。
排查过程:
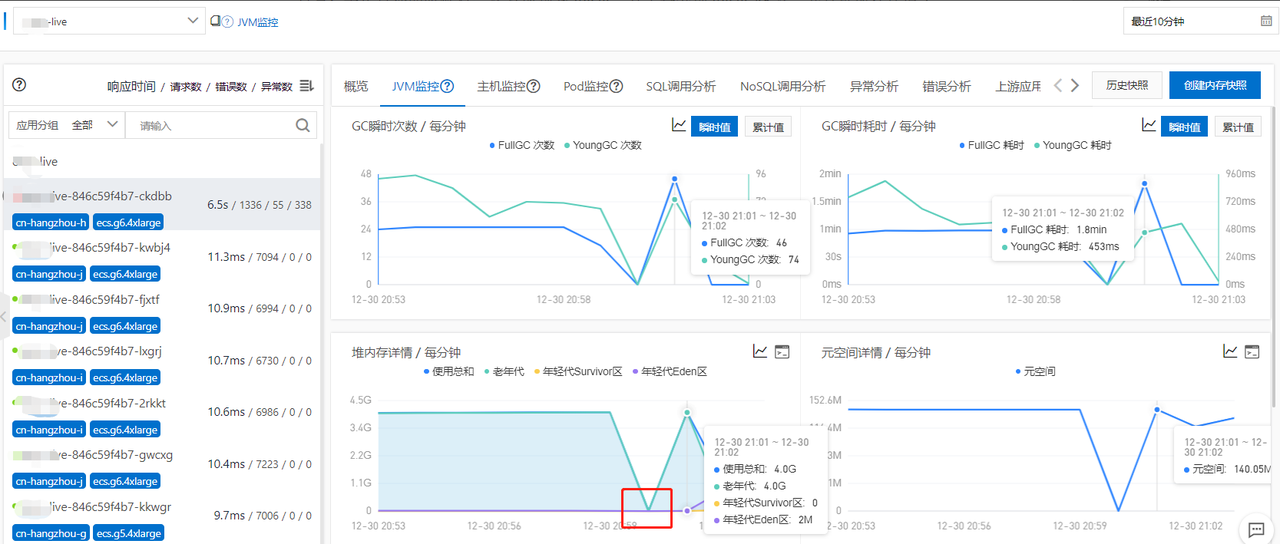
1.从阿里云ARMS(应用实时监控服务)的JVM监控中观察到live服务频繁full gc,甚至一分钟46次。full gc耗时1.8min,young gc耗时453ms。老年代对象占满了4g,并且gc完还是这么大,大概率是发生了内存泄漏。可以看到红框这个时刻对象占用内存突然变成0了,其实就是发生OOM,重启了。这时候应该先把内存dump下来,分析一下看出现了什么问题。
2.进入pod(命令sudo kubectl exec -it {pod name} -n prod bash)
3.安装open jdk。yum -y install java-1.8.0-openjdk-devel
4.使用jps查看当前节点的java线程。
5.使用jmap 生成堆转存文件。
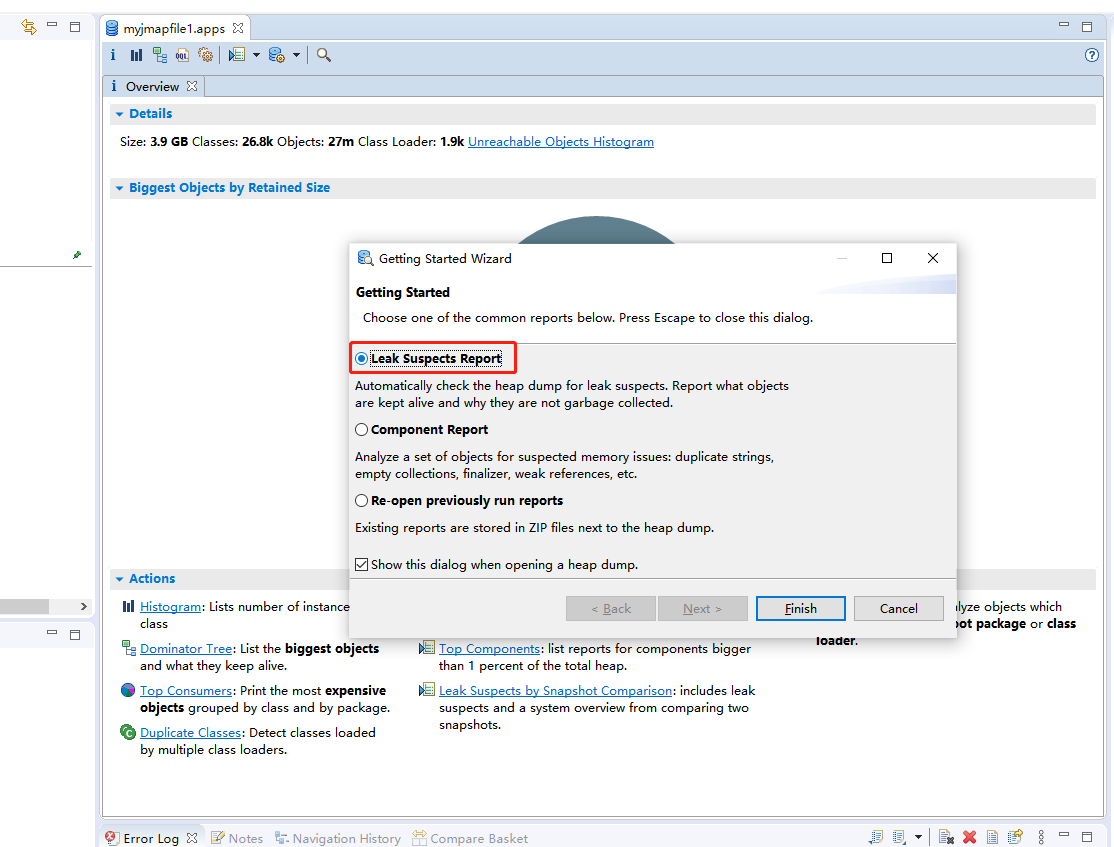
6.使用eclipse mat工具打开堆转存文件,生成内存泄漏怀疑分析报告(leak suspects report)
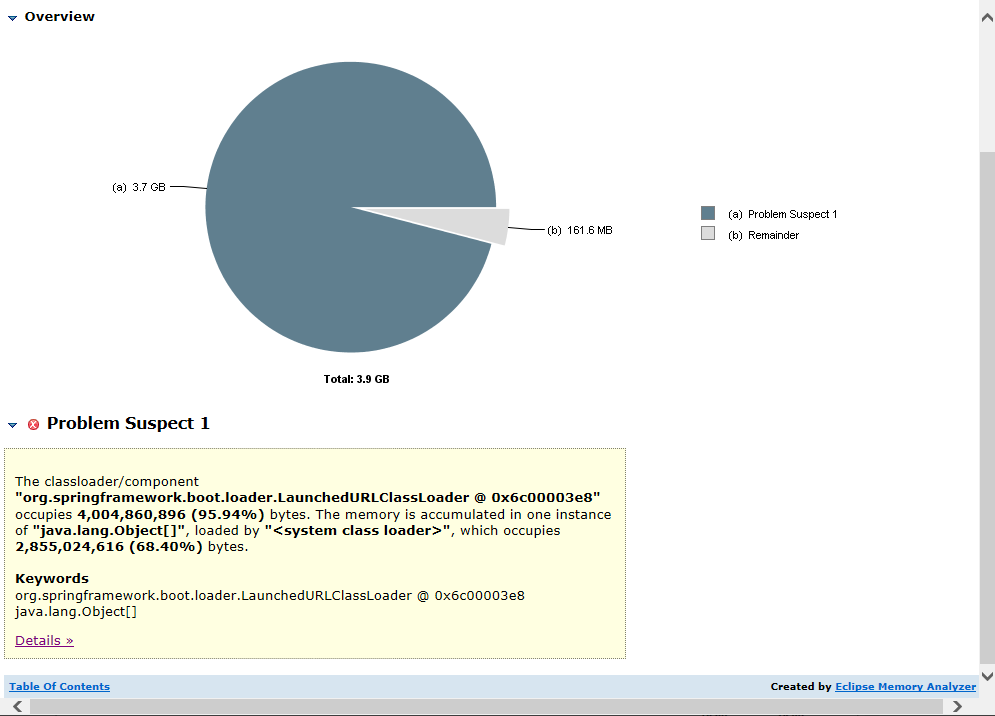
7.打开内存泄漏怀疑分析报告,能看出某个队列的类名,它占用了3.7g的内存
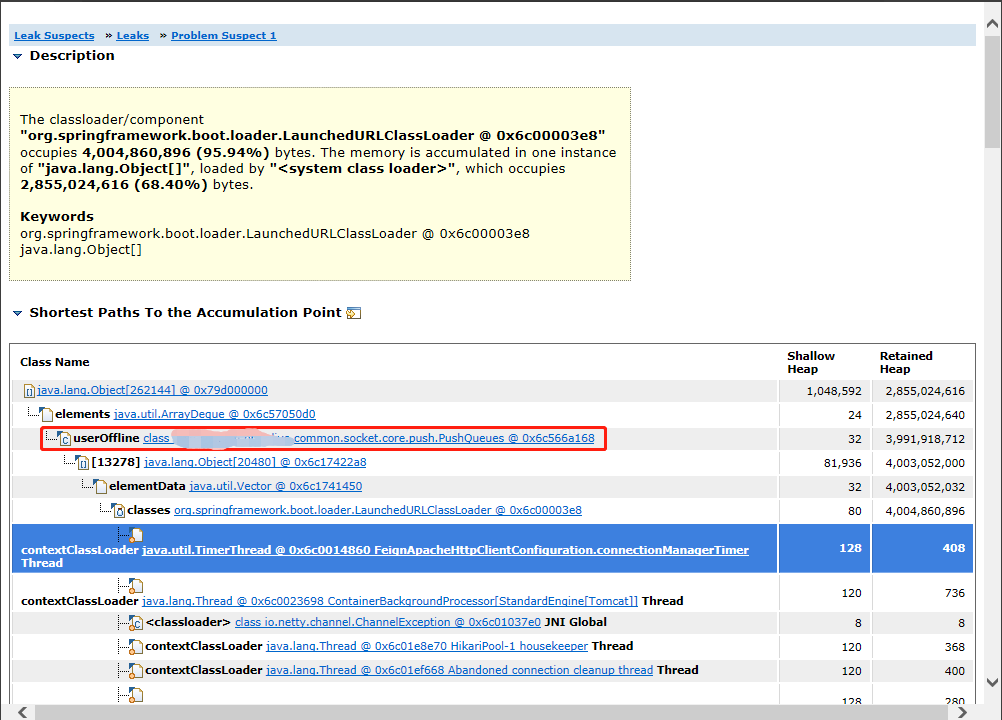
8.最终发现是一个无界队列,用于异步发送弹幕、进入房间提醒、商品购买弹幕消息。使用定时任务消费队列任务,每分钟100条。消费速度远远跟不上生产速度,导致oom。
9.后面改成了使用ThreadPoolExecutorService+有界队列异步消费弹幕消息。在观众的弹幕发送接口,加上了限流,这里就不赘述了。

后记:可以使用JVM参数:-XX:-HeapDumpOnOutOfMemoryError、-XX:HeapDumpPath={文件路径}.hprof指定发生oom时,自动生成当时的堆转存文件。如果使用这个参数,注意要配置pod的回收速度要慢一些,不然文件还没生成出来,pod就被删掉了